class: center, top  <!-- Do not forget to adapt the presentation title in the header! --> <!-- Adjust the presentation to the session. Focus on the challenges, this is not a coding tutorial. Note, to include figures, store the image in the `/docs/assets/images` folder and use the jekyll base.url reference as done in this template or see https://jekyllrb.com/docs/liquid/tags/#links. using the scale attribute , you can adjust the image size. --> <!-- Adjust the day, month --> # 25 APRIL 2024 ## INBO coding club <!-- Adjust the room number and name --> Herman Teirlinck 01.71 - Frans Breziers --- class: left, top ## ROOMIE: room reservation ``` > if (isFALSE(roomie)) { + warning("Please confirm asap the room reservation on the roomie") + } Warning message: Please confirm asap the room reservation on the roomie ``` --- class: left, top ## Record the session Kind reminder to... myself. --- class: left, top ## New Hex Stickers We have finally new INBO coding club stickers! You can be the first one to have one.  --- class: center, middle <!-- Create a new badge using Inkscape based on the assets/images/coding_club_badges.svg file -->  --- class: left, top The dplyr cheat sheet is available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_data_transformation.pdf) or as [html](https://rstudio.github.io/cheatsheets/html/data-transformation.html). 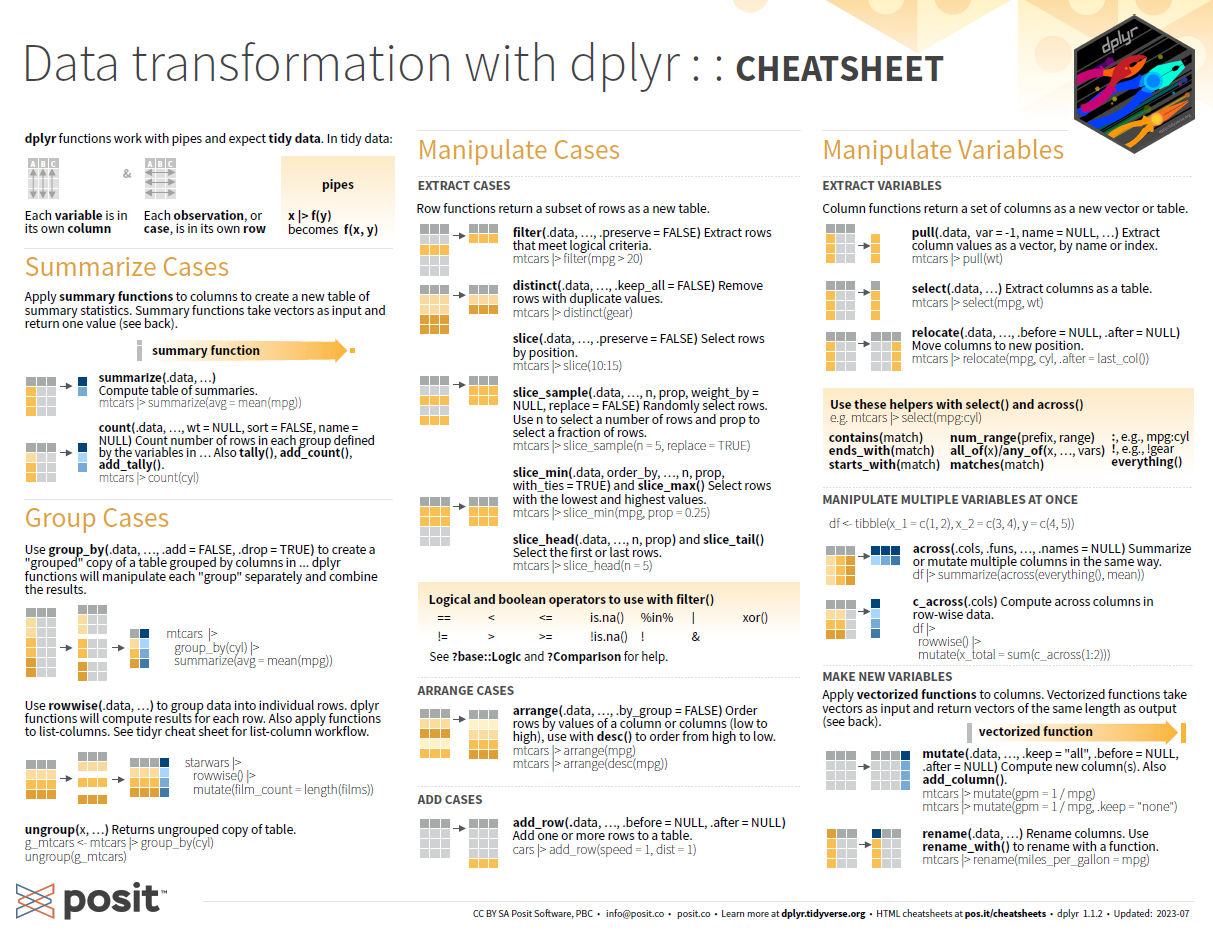 New to dplyr? The best resource for self study is the [data transformation chapter](https://r4ds.had.co.nz/transform.html) in R for data science. --- class: left, top You could benefit of the cheatsheets of other two important tidyverse packages: tidyr and purrr. - [tidyr](https://tidyr.tidyverse.org/): cheasheet available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_tidyr.pdf) or [html](https://rstudio.github.io/cheatsheets/html/tidyr.html). - [purrr](https://purrr.tidyverse.org/): cheasheet available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_purrr.pdf) or [html](https://rstudio.github.io/cheatsheets/html/purrr.html). <center></center> <center></center> --- class: left, top ## How to get started? Check the [Each session setup](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup) to get started. ## First time coding club? Check the [First time setup](https://inbo.github.io/coding-club/gettingstarted.html#first-time-setup) section to setup. --- class: left, top  --- class: center, top # Share your code during the coding session <!-- Create a new hackmd file and replace this link (twice!) --> Go to https://hackmd.io/bQqDeUHUQSqJ9reMykkM2A?both and start by adding your name in section "Participants". <iframe src="https://hackmd.io/bQqDeUHUQSqJ9reMykkM2A?edit" height="400px" width="800px"></iframe> --- class: left, top # Download data and code You can download the material of today: - automatically via `inborutils::setup_codingclub_session()`* - manually** from GitHub folders [data/20240425](https://github.com/inbo/coding-club/tree/master/data/20240425) and [src/20240425](https://github.com/inbo/coding-club/tree/master/src/20240425) <br> <small> __\* Note__: you can use the date in "YYYYMMDD" format to download the coding club material of a specific day, e.g. run `setup_codingclub_session("20230228")` to download the coding club material of February, 28 2023. If date is omitted, i.e. `setup_codingclub_session()`, the date of today is used. For all options, check the [tutorial online](https://inbo.github.io/tutorials/tutorials/r_setup_codingclub_session/).</small> <br> <small> __\*\* Note__: check the getting started instructions on [how to download a single file](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup)</small> --- class: left, top # Data and scripts description Today we will work with: - [20240425_observations.csv](https://github.com/inbo/coding-club/blob/main/data/20240425/20240425_observations.csv) and [20240425_media.csv](https://github.com/inbo/coding-club/blob/main/data/20240425/20240425_media.csv): observations and media tables of a Camera Trap Data Package*. Derived from the [camtrap-dp](https://github.com/tdwg/camtrap-dp/tree/02ce57229209dd65249113a193dbad7c84b8d5da/example) package. - [20240425_si_species_per_year_cell.csv](https://github.com/inbo/coding-club/blob/main/data/20240425/20240425_si_species_per_year_cell.csv): comma separated value file with the species (`speciesKey` column) present in each EEA (European Environment agency) cell code of 1km x 1km (`eea_cell_code` column) per year (`year` column) of Slovenia (country code: SI). Source: extracted from the [Slovenian occurrence cube](https://zenodo.org/records/10528506). - [20240425_ias_plants.csv](https://github.com/inbo/coding-club/blob/main/data/20240425/20240425_ias_plants.csv): a list of invasive alien plants. One column contains the scientific names, while the others contain vernacular names in English, Dutch and French. - [20240425_challenges.R](https://github.com/inbo/coding-club/blob/master/src/20240425/20240425_challenges.R): R script to start from (some code is already provided) <small> \* Website: https://camtrap-dp.tdwg.org/. Do you know that INBO has been and still is actively involved in the development of this data exchange format? Ask Peter Desmet :-) </small> --- class: left, top # Why dplyr? A lot of reasons. But the main one is that it makes the code easy to read (in comparison with basic R). Other important reasons? - It is actively maintained (people from posit, the company behind RStudio). - It works nicely with all other tidyverse packages. - Its development is open on [GitHub](https://github.com/tidyverse/dplyr/): issues, questions, dev ideas etc. are welcome. - Its functions have very good names. Some of them are exactly the same as in SQL, e.g. `filter()`, `select()`. --- background-image: url(/assets/images/background_challenge_1.png) class: left, top # Challenge 1 - Single table verbs [Single table verbs](https://dplyr.tidyverse.org/articles/dplyr.html#single-table-verbs) = functions working on one data.frame. After reading the camera trap observations as a dataframe called `obs` (code provided): 1. Display first 8 rows; display the last 8 rows. 2. Select columns `observationLevel`, `eventStart`, `eventEnd` and `scientificName` 3. Display the **distinct** values of `observationLevel` as a data.frame with one column, `observationLevel`. How many different values of `observationLevel` are there? 4. How to remove observations with `observationLevel` = `"media"`? How to remove observations with `observationLevel` = `"media"` and empty `scientificName`? 5. Add a new column called `is_classified_by_human` which is TRUE if `classificationMethod` is equal to `"human"`. Add a new column `month` with the month of the observation (`eventStart`). Tip: use lubridate's `month()` and `year()` functions. 6. Move the column `count` after `behavior`. 7. Move all columns starting with `"individual"` before `observationLevel` 8. Is the following statement true or false: Observations with `observationLevel` = `"event"` have no `mediaID`, i.e. `mediaID` is `NA`. --- class: left, top ## Intermezzo - The pipe %>% From [dplyr](https://dplyr.tidyverse.org/articles/dplyr.html#the-pipe) documentation:  Can you apply the pipe to combine some steps of challenge 1? --- background-image: url(/assets/images/background_challenge_2.png) class: left, top # Challenge 2 - Single table verbs: summaries 1. How many observations are there per deploymentID? Show it as a dataframe with two columns: `deploymentID` and `n_obs`. 2. How many observations are there per `deploymentID` and `observationLevel`? 3. Order the previous output per `n_obs` (descending order). 4. Create a summary dataframe with the number of media-based observations (`observationLevel` = "media"), the number of event-based observations (`observationLevel` = "event") and the total number of observations per `deploymentID`. Notice that `observationLevel` is always filled in. The result should be a dataframe with 4 columns: `deploymentID`, `n_obs_event`, `n_obs_media` and `n_obs`. Tip: one way to solve this is by combining dplyr with tidyr. 5. For each month, year and `deploymentID`, return the `eventStart` of the first and the last event-based observation (observationLevel = `event`) if there are 3 or more event-based observations. Call these two columns `first_event_obs` and `last_event_obs` respectively. 6. How can you return the same dataframe as in exercice 5 but now limiting us to the months with the highest number of event-based observations for each year and `deploymentID`? --- class: left, top ## Intermezzo - dplyr is a living thing We said at the beginning that dplyr is actively being maintained. There is more! dplyr had moved and is actually moving forward to get better and better. dplyr released an important new version in early 2023, dplyr 1.1.0. At the moment, we are at version 1.1.4. This means new, very nice functions have been added, but other, older functions got superseded or some arguments deprecated etc. Read more in these 4 blogposts: - [dplyr 1.1.0: joins](https://www.tidyverse.org/blog/2023/01/dplyr-1-1-0-joins/) - [dplyr 1.1.0: Per-operation grouping](https://www.tidyverse.org/blog/2023/02/dplyr-1-1-0-per-operation-grouping/) - [dplyr 1.1.0: The power of vctrs](https://www.tidyverse.org/blog/2023/02/dplyr-1-1-0-vctrs/) - [dplyr 1.1.0: pick(), reframe(), and arrange()](https://www.tidyverse.org/blog/2023/02/dplyr-1-1-0-pick-reframe-arrange/) --- class: left, top ## Intermezzo - Two-table verbs Two-table verbs = functions which take two data.frames as input to typically return one data.frame as output. A nice [article](https://dplyr.tidyverse.org/articles/two-table.html) on dplyr website. The most famous two-table function family is the "join" family. Have a look at the [news about joins](https://www.tidyverse.org/blog/2023/01/dplyr-1-1-0-joins/)* also mentioned in previous slide.  <br> <small> __\* Note__: the cheatsheet doesn't reflect the new features shown in the article.</small> --- background-image: url(/assets/images/background_challenge_3.png) class: left, top # Challenge 3 - Two-table verbs After reading the camera trap media information as a dataframe called `media` (code provided): 1. How to add the media information stored in `media` to the observations? 2. How are the columns ordered? Are the columns from observations on the left? Try to put them on the right. 3. Are there media not in observations, i.e. are there media that are not linked to any observation? 4. Some observations have a missing value for column `mediaID`. Get rid of them while joining. 5. As deploymentID is present in both dataframes, it gets duplicated and the suffixes `".x"` and `".y"` are added. How to change the suffixes to `"_obs"` and `"_media"` while performing exercise 1? 6. How to add the suffix only for the column `deploymentID` in `media`? 7. How can you avoid having this column twice? --- class: left, top # dplyr is a living thing An example: ``` people <- tibble( first_name = c("Amber", "Damiano", "Dirk", "Emma", "Raïsa", "Rhea"), second_name = c("Mertens", "Oldoni", "Maes", "Cartuyvels", "Carmen", "Maesele") ) hobbys <- tibble( # purely invented! people = c("Hans", "Damiano", "Dirk", "Amber", "Emma", "Raïsa"), sport = c("rugby", "football", "hockey", "ski", "tennis", "bowling") ) # old dplyr, still works! You need "" = "". people %>% left_join(hobbys, by = c("first_name" = "people") ) # now you can use join_by() and colnames without " " people %>% left_join(hobbys, join_by(first_name == people)) ``` --- class: left, top # Bonus challenge 1 - Create tidy data Sometimes, the first data manipulation you have to perform is to create tidy data. dplyr might not suffice: you will need another important tidyverse package: [tidyr](https://tidyr.tidyverse.org/). Tidy data is data where: - Every column is variable. - Every row is an observation. - Every cell is a single value. --- class: left, top # Bonus challenge 1 - dplyr + tidyr = love Probably you have already used tidyr to solve one of the previous exercises. Still, its importance is worth another exercise. After reading `20240425_ias_plants.txt` dataset (code provided), make it tidy. Please notice that two vernacular names of the same language are given for some species, e.g. "gewone gunnera;reuzenrabarber". They should be split as two rows. <center></center> --- class: left, top # Bonus challenge 2 - dplyr + stringr = love We said that dplyr matches nicely with other tidyverse packages. Example: stringr in this case. stringr has a very convenient function to **rank** people by their favorite numbers. Notice that the heading zeros must remain in the output. ``` a <- tibble( name = c("Damiano", "Amber", "Rhea", "Dirk", "Emma", "Raïsa"), my_favorite_number_string = c("104", "023", "07", "O666", "3", "9") ) ## Add the commando here to get this output: # A tibble: 6 × 2 name my_favorite_number_string <chr> <chr> 1 Emma 3 2 Rhea 07 3 Raïsa 9 4 Amber 023 5 Damiano 104 6 Dirk 0666 ``` --- class: left, top # Bonus challenge 3 - dplyr + tidyverse = love For this challenge it _could_ be that you need to use dplyr in combination with other tidyverse packages. And that's fine! After reading `20240425_si_species_per_year_cell.csv` dataset (code provided): 1. Calculate the cumulative number of species observed over time (`year`) in each square (`eea_cell_code`). 2. Find the 10 cells with the highest cumulative number of species. Thanks Hans for the core of this challenge. --- class: left, top # Bonus challenge 4 - lists + purrr = love Sometimes your data are encapsulated lists. That's where purrr can rescue you. A typical situation is parsing JSON files. Read the ETN's datapackage json as `datapackage_json` (code provided) and pick some information to transform it to a data.frame as shown here below. Thanks Pieter for the challenge and the [solution](https://gist.github.com/PietrH/c2c5be775a54da21e8b09c947b279fb5). 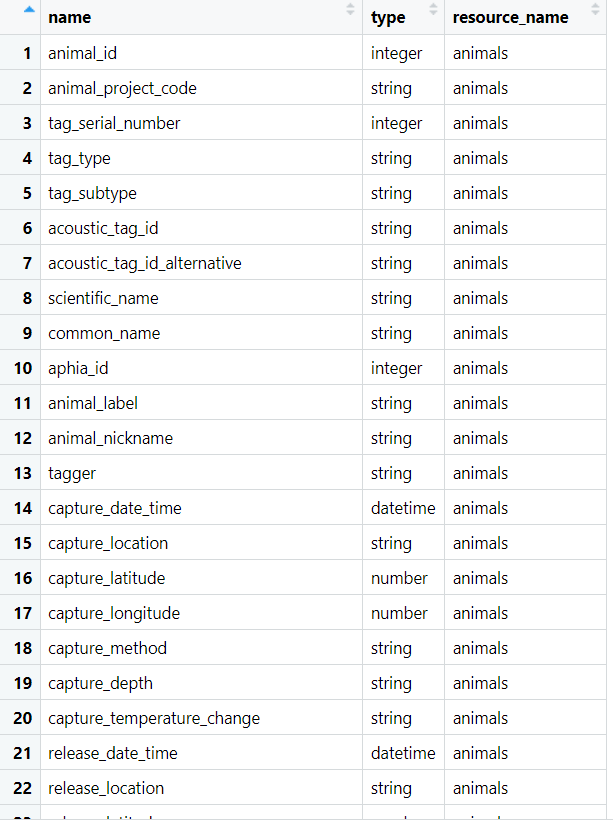 --- class: left, top # The package of the month. Damiano's choice [tidylog](https://github.com/elbersb/tidylog): provides feedback about dplyr and tidyr operations. I like it a lot, especially while joining dataframes or using long pipes: ``` library(tidylog) > band_members %>% inner_join(band_instruments) Joining with `by = join_by(name)` inner_join: added one column (plays) > rows only in x (1) > rows only in y (1) > matched rows 2 > === > rows total 2 ``` ``` mtcars %>% select(mpg, cyl, hp, am) %>% filter(mpg > 15) %>% mutate(mpg_round = round(mpg)) %>% group_by(cyl, mpg_round, am) %>% tally() %>% filter(n >= 1) #> select: dropped 7 variables (disp, drat, wt, qsec, vs, …) #> filter: removed 6 rows (19%), 26 rows remaining #> mutate: new variable 'mpg_round' (double) with 15 unique values and 0% NA #> group_by: 3 grouping variables (cyl, mpg_round, am) #> tally: now 20 rows and 4 columns, 2 group variables remaining (cyl, mpg_round) #> filter (grouped): no rows removed ``` --- class: left, top # Resources - The commented [solutions](https://github.com/inbo/coding-club/blob/main/src/20240425/20240425_challenges_solutions.R) are available. You can download them automatically via `inborutils::setup_codingclub_session("20240425")`. - The edited [video recording](https://vimeo.com/940822870?share=copy) is available on our [vimeo channel](https://vimeo.com/user/8605285/folder/1978815). - [dplyr cheat sheet](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_data_transformation.pdf). - [tidyr cheat sheet](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_tidyr.pdf). - [purrr cheat sheet](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240425_cheat_sheet_purrr.pdf). - [dplyr](https://dplyr.tidyverse.org/) package documentation. - [tidyr](https://tidyr.tidyverse.org/) package documentation. - [purrr](https://purrr.tidyverse.org/) package documentation. - [data transformation chapter](https://r4ds.had.co.nz/transform.html) in the [R for data science](https://r4ds.had.co.nz/index.html) book. - [tidylog](https://github.com/elbersb/tidylog) package. - Source of the bonus challenge 4: a Pieter's [GitHub gist](https://gist.github.com/PietrH/c2c5be775a54da21e8b09c947b279fb5). --- class: left, top # Coding club topic of May? Every month you can vote among **two topics**. Poll for May's coding club will be launched soon! <center></center> <bottom><small>Image source: https://learn.e-limu.org/topic/view/?t=248&c=46</small></bottom> --- class: center, middle  <!-- Adjust the room number and name --> Topic: to be decided <br> Room: HT - 01.18 - Joseph Poelaert(?) <br> Date: **28/05/2024**, from **10:00** to **12:30** <br> Help needed with technical setup? You are welcom from **9:45am**