class: center, top  <!-- Do not forget to adapt the presentation title in the header! --> <!-- Adjust the presentation to the session. Focus on the challenges, this is not a coding tutorial. Note, to include figures, store the image in the `/docs/assets/images` folder and use the jekyll base.url reference as done in this template or see https://jekyllrb.com/docs/liquid/tags/#links. using the scale attribute , you can adjust the image size. --> <!-- Adjust the day, month --> # 30 JANUARY 2025 ## INBO coding club <!-- Adjust the room number and name --> Herman Teirlinck<br> 01.70 - Ferdinand Peeters <br> --- class: left, top ## ROOMIE: room reservation ``` > if (isFALSE(roomie)) { + warning("Please confirm asap the room reservation on the roomie") + } Warning message: Please confirm asap the room reservation on the roomie ``` --- class: left, top ## Welcome Oberon to the core team 👋 Oberon Geunens (team "Estuaries") is the new member of the INBO coding club core team. He will replace Amber Mertens. He is a data scientist with a passion for spatial data visualization. --- class: left, top ## INBO coding club goes to FOSDEM'25 - [**FOSDEM**](https://fosdem.org/2025/) is a free event for software developers to meet, share ideas and collaborate. Every year, thousands of developers of free and open source software from all over the world gather at the event in Brussels. You don't need to register. Just turn up and join in! - Lightning talk about our club will be given at the dev room "Open Research": see [timetable](https://fosdem.org/2025/schedule/track/research/). 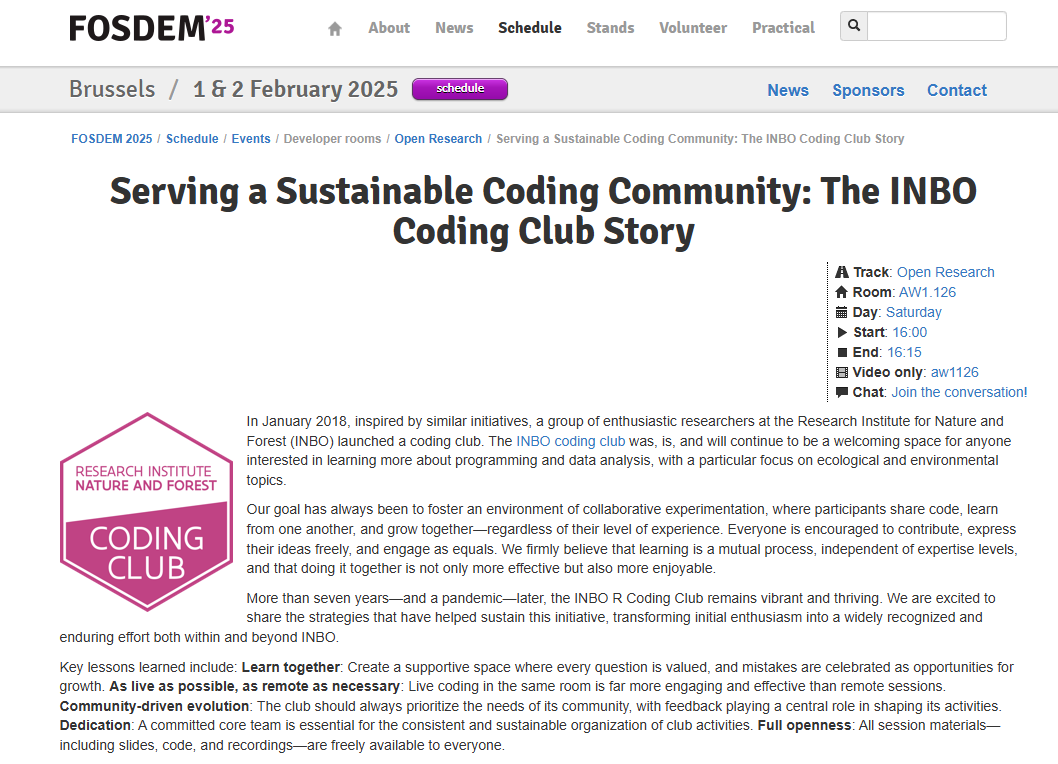 --- class: center, middle <!-- Create a new badge using Inkscape based on the assets/images/coding_club_badges.svg file -->  --- class: left, top The dplyr cheat sheet is available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20250130_cheat_sheet_data_transformation.pdf) or as [html](https://rstudio.github.io/cheatsheets/html/data-transformation.html).  New to dplyr? The best resource for self study is the [data transformation chapter](https://r4ds.had.co.nz/transform.html) in R for data science. --- class: left, top You could benefit of the cheatsheets of other two important tidyverse packages: tidyr and purrr. - [tidyr](https://tidyr.tidyverse.org/): cheatsheet available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20250130_cheat_sheet_tidyr.pdf) or [html](https://rstudio.github.io/cheatsheets/html/tidyr.html). - [purrr](https://purrr.tidyverse.org/): cheatsheet available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20240627_cheat_sheet_purrr.pdf) or [html](https://rstudio.github.io/cheatsheets/html/purrr.html). <center></center> <center></center> --- class: left, top ## How to get started? Check the [Each session setup](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup) to get started. ## First time coding club? Check the [First time setup](https://inbo.github.io/coding-club/gettingstarted.html#first-time-setup) section to setup. --- class: left, top 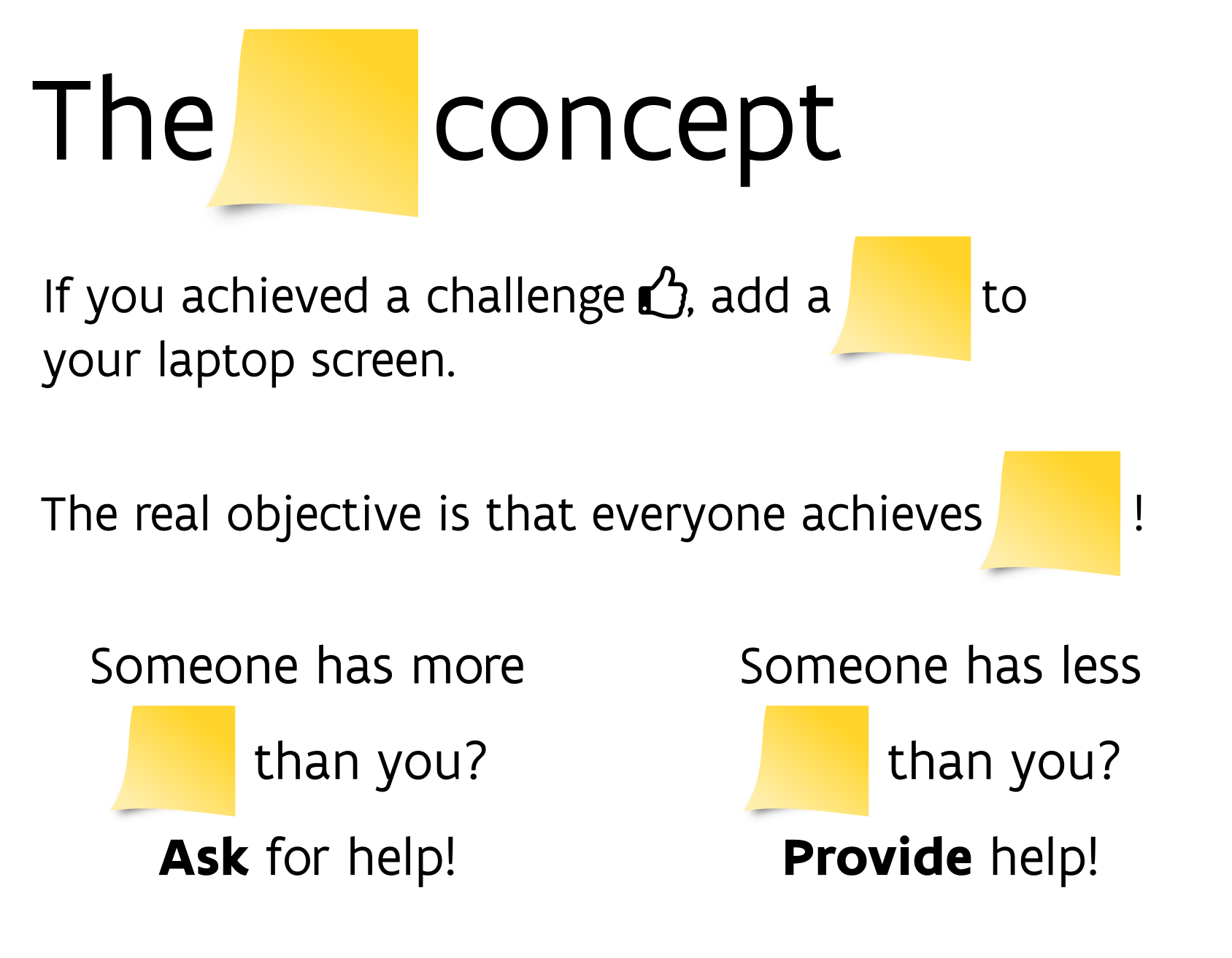 --- class: center, top # Share your code during the coding session <!-- Create a new hackmd file and replace this link (twice!) --> Go to https://hackmd.io/@damianooldoni/HJM0WEu_1l?both and start by adding your name in section "Participants". <iframe src="https://hackmd.io/@damianooldoni/HJM0WEu_1l?edit" height="400px" width="800px"></iframe> --- class: left, top # Why dplyr? A lot of reasons. But the main one is that it makes the code easy to read (in comparison with basic R). Other important reasons? - It is actively maintained (people from posit, the company behind RStudio). - It works nicely with all other tidyverse packages. - Its development is open on [GitHub](https://github.com/tidyverse/dplyr/): issues, questions, dev ideas etc. are welcome. - Its functions have very good names. Some of them are exactly the same as in SQL, e.g. `filter()`, `select()`. --- class: left, top # The pipe %>% operator From [dplyr](https://dplyr.tidyverse.org/articles/dplyr.html#the-pipe) documentation:  Which code version is more readable? ``` library(dplyr) # Version 1 mtcars %>% filter(mpg > 20) %>% select(mpg, cyl, hp) # Version 2 select(filter(mtcars, mpg > 20), mpg, cyl, hp) ``` RStudio provides a shortcut to insert a pipe: `Ctrl + Shift + M`. --- class: left, top # Pipe %>% or pipe |> From [tidyverse blogpost](https://www.tidyverse.org/blog/2023/04/base-vs-magrittr-pipe/) R 4.1.0 introduced a native pipe operator, |>. As described in the R News: > R now provides a simple native forward pipe syntax |>. The simple form of the forward pipe inserts the left-hand side as the first argument in the right-hand side call. The pipe implementation as a syntax transformation was motivated by suggestions from Jim Hester and Lionel Henry. See section ["|> vs. %>%"](https://www.tidyverse.org/blog/2023/04/base-vs-magrittr-pipe/#-vs) to know the slightly different behavior of the two pipes. --- class: left, top # Download data and code You can download the material of today: - automatically via `inborutils::setup_codingclub_session()`* - manually** from GitHub folders [data/20250130](https://github.com/inbo/coding-club/tree/master/data/20250130) and [src/20250130](https://github.com/inbo/coding-club/tree/master/src/20250130) <br> <small> __\* Note__: you can use the date in "YYYYMMDD" format to download the coding club material of a specific day, e.g. run `setup_codingclub_session("20230228")` to download the coding club material of February, 28 2023. If date is omitted, i.e. `setup_codingclub_session()`, the date of today is used. For all options, check the [tutorial online](https://inbo.github.io/tutorials/tutorials/r_setup_codingclub_session/).</small> <br> <small> __\*\* Note__: check the getting started instructions on [how to download a single file](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup)</small> --- class: left, top # Data and scripts description Today we will work with: - [20250130_butterflies_eu.csv](https://github.com/inbo/coding-club/blob/main/data/20250130/20250130_butterflies_eu.csv): taxon core of the GBIF checklist: ["National checklists and red lists for European butterflies"](https://www.gbif.org/dataset/f9af6ffd-febc-4626-b2e8-809b1c60fa01#description). - [20250130_butterflies_eu_distributions.csv](https://github.com/inbo/coding-club/blob/main/data/20250130/20250130_butterflies_eu_distributions.csv): distribution extension of the "National checklists and red lists for European butterflies". It contains the distribution of the species at country level, especially the threat status. - [20250130_butterflies_eu_vernacularnames_dutch_all_GBIF.csv](https://github.com/inbo/coding-club/blob/main/data/20250130/20250130_butterflies_eu_vernacularnames_dutch_all_GBIF.csv): all Dutch vernacular names found on GBIF related to the butterflies listed in the "National checklists and red lists for European butterflies". - [20250130/20250130_transect_counts.csv](https://github.com/inbo/coding-club/blob/main/data/20250130/20250130_transect_counts.csv): butterfly transect count. Derived from `20250130_butterfly_transect_counts_raw.xls`. - [20250130_butterfly_transect_counts_raw.xls](https://github.com/inbo/coding-club/blob/main/data/20250130/20250130_butterfly_transect_counts_raw.xls): raw and untidy transect counts Excel sheet. Only needed in Bonus Challenge 2. - [20250130_challenges.R](https://github.com/inbo/coding-club/blob/master/src/20250130/20250130_challenges.R): R script to start from (some code is already provided) <small> \* More info about this monitoring method in ["Butterfly Transect Counts - Manual to Monitor Butterflies"](https://butterfly-monitoring.net/sites/default/files/Publications/Butterfly%20Transect%20Counts-Manual%20v1.pdf). Sevilleja, C.G.1, van Swaay, C.A.M.1,2, Bourn, N.3, Collins, S.2, Settele, J.4, Warren, M.S.2, Wynhoff, I.2 and Roy, D.B.5 (2019). Butterfly Transect Counts: Manual to monitor butterflies. Report VS2019.016, Butterfly Conservation Europe & De Vlinderstichting/Dutch Butterfly Conservation, Wageningen. </small> --- background-image: url(/assets/images/background_challenge_1.png) class: left, top ## Challenge 1 - basics 1. Get the unique values of column `threatStatus` in `butterflies_eu_distr_all`. (Bonus: both as vector (basic R) or data.frame with 1 one column (dplyr)). 2. Remove the rows without `country`, i.e. the data at European level. Save it as `butterflies_eu_distr`. 3. Count the number of taxon keys (column `taxonKey`) for each `threatStatus`. 4. Count the number of taxon keys (column `taxonKey`) for each `threatStatus` and country. 5. Order the count of taxon keys (column `taxonKey`) for each `threatStatus` and `country` in descending order. 6. Remove columns `source` and `remarks` from `butterflies_eu_distr`. 7. Move column `country` between `taxonKey` and `locality`. Move `threatStatus` after `locationId`. 8. Optional. Sometimes we cannot know in advance that the columns we want to select/remove from a data.frame exist. For example, how to remove `source` and `remarks` without returning an error if they do not exist? --- background-image: url(/assets/images/background_challenge_2.png) class: left, top ## Challenge 2 - To join or not to join 🦋 1. **Filter** `butterflies_eu` to get only the Belgian butterflies (country code: `BE` in `butterflies_eu_distr`). Save the result as `butterflies_be`. Important: no need to join the two datasets! 2. Some countries haven't reported the `threatStatus` (threatStatus = NA) for any species in `butterflies_eu_distr`. Which ones? Important: many countries reported the `threatStatus` for some species, but not for all of them and should be excluded. 3. The `transect_counts` dataset contains the counts of butterflies in a transect. The column `species` contains the Dutch vernacular names of the butterflies. Add to `transect_counts` a column called `scientificName` with the scientific name contained in `butterflies_be` (column `scientificName`). You can do this by matching the vernacular names in `transect_counts$species` with the vernacular names contained in `butterflies_eu_vern_dutch$vernacularName`. Tip 1: use `butterflies_eu_vern_dutch$taxonKey` and `butterflies_be$nubKey` for comparing/joining. Tip 2: comparing the lower case version of the vernacular names can be useful to avoid mismatches due to capitalization. --- class: left, top ## Intermezzo: rgbif + purrr = 💪 It's almost impossible to do data wrangling with tidyverse without using [purrr](https://purrr.tidyverse.org/). purrr is a package from tidyverse ecosystem. It allows you to write code in a more functional style, which can be more readable and maintainable. [rgbif](https://docs.ropensci.org/rgbif/) is an R package to interface with the [Global Biodiversity Information Facility](https://www.gbif.org/) (GBIF) [API](https://techdocs.gbif.org/en/openapi/). It allows you to search for species, download occurrence data, and more. purrr and rgbif can be combined to make powerful and flexible workflows. Let's show some examples of how you can use them together to get vernacular names.  --- class: left, top ## Intermezzo: rgbif + purrr = 💪 The "National checklists and red lists for European butterflies" dataset contains only vernacular names in English. Just check it via: ``` purrr::map( butterflies_eu$key, function(x) { rgbif::name_usage(key = x, data = "vernacularNames") %>% purrr::pluck("data") }) %>% purrr::list_rbind() %>% dplyr::distinct(language) ``` --- class: left, top ## Intermezzo: rgbif + purrr = 💪 We are interested in the Dutch vernacular names. How to get them? Let's do it by using the GBIF Taxonomic Backbone! The field `nubKey` in `butterflies_eu` contains the key of the taxon in the GBIF Taxonomic Backbone. We can use it to get the Dutch vernacular names of the Belgian butterflies: ``` butterflies_eu_vern_dutch <- purrr::map( butterflies_eu$nubKey, function(x) { rgbif::name_usage(key = x, data = "vernacularNames") %>% purrr::pluck("data") }) %>% purrr::list_rbind() %>% dplyr::filter(language == "nld") ``` `butterflies_eu_vern_dutch` is actually the data.frame saved as `20250130_butterflies_eu_vernacularnames_dutch_all_GBIF.csv`. Curious about purrr? Check the INBO coding club session of [Jun 27, 2024](https://coding-club.inbo.be/sessions/20240627_functional_programming_in_r.html#1). --- background-image: url(/assets/images/background_challenge_3.png) class: left, top ## Challenge 3 - So many names, so little time 🦋 1. The data.frame `butterflies_eu_vern_dutch` contains several vernacular names for the same species (`taxonKey`). Some of them are exactly the same: they are just collected from different checklists. How many unique vernacular names are there for each taxon? 2. We can see that some unique vernacular names are just the same name written in different ways. For example, "Atalanta" and "atalanta". How many unique vernacular names are there for each taxon if we ignore the case/capitalization? Return a data.frame with two columns: `taxonKey` and `n`. Order the result by `n`, from high to low. Tip: stringr package can be useful. 3. The previous result means that we need to make some choices: vernacular names are not only written in different ways, but they ARE sometimes really different! Example: "akkerparelmoervlinder" and "paarse parelmoervlinder". Before making a choice, let's analyse the situation. Instead of counting only, return a data.frame with three columns: `taxonKey`, `vernacularName_lower` (lowercase version of `vernacularName`) and `n_names` (number of vernacular names). Again, order the output by `n_names`, from high to low. --- class: left, top # Bonus challenge 1 - choices 🤷 Input: `butterflies_eu_vern_dutch`. It's time to make choices. In case of multiple vernacular names, the expert (our Dirk) indicated most of the time the preferred vernacular name source via column `preferred` (`preferred` = `TRUE`). So, keep only the rows with `preferred` = `TRUE` for each taxon. Select the first vernacular name if there is no preferred one. If there is only one vernacular name, just keep that. Return a data.frame called `butterflies_eu_vern_dutch_preferred` with same columns as `butterflies_eu_vern_dutch`. --- class: left, top # Bonus challenge 2 - tidying up your data 🧹 Making use of readxl package, load the data from the Excel file `20250130_butterfly_transect_count_raw.xlsx` and save it as `transect_counts`. The data is in a messy format. Can you tidy it up? Apply the tidy data principles *: > Tidy datasets are easy to manipulate, model and visualize, and have a specific structure: each variable is a column, each observation is a row, and each type of observational unit is a table. At least, you should be able to return the data.frame `transect_counts` saved in `20250130_transect_counts.csv`. Which are the other observational units? How to link all tables? You will need to create unique identifiers. Which columns can be used for this? <small> \* More info about tidy data in ["Tidy Data"](https://vita.had.co.nz/papers/tidy-data.pdf). Wickham, H. (2014). Tidy Data. Journal of Statistical Software, 59(10), 1-23. --- class: left, top # Package of the month: tidylog I know, it's not the first time we choose tidylog as package of the month. But it's so useful! tidylog is a package that extends the dplyr/tidyr packages. It allows you to log the output of dplyr/tidyr functions. This can be very useful when you are working with a lot of data and you want to check the output of your code. Give a look to its [README](https://github.com/elbersb/tidylog/?tab=readme-ov-file#tidylog) with some interesting examples. --- class: left, top # Resources 1. Extended [challenges solutions](https://github.com/inbo/coding-club/blob/main/src/20250130/20250130_challenges_solutions.R) are available. You can opt to download them automatically by using `inborutils::setup_codingclub_session("20250130")`. No video recording this time, sorry! 2. [dplyr homepage](https://dplyr.tidyverse.org/). 3. [tidyr homepage](https://tidyr.tidyverse.org/). 4. [purrr homepage](https://purrr.tidyverse.org/). 5. [data transformation chapter](https://r4ds.hadley.nz/transform.html) in [R for data science 2nd edition.](https://r4ds.hadley.nz/). 6. [rgbif homepage](https://docs.ropensci.org/rgbif/). 7 The [GBIF API](https://techdocs.gbif.org/en/openapi/) documentation. 8. The game changing article of Hadley Wickham: [Tidy Data](https://vita.had.co.nz/papers/tidy-data.pdf), from 2014. 9. [readxl homepage](https://readxl.tidyverse.org/). 10. [tidylog homepage](https://github.com/elbersb/tidylog): no fancy package website, but still well written `README`. --- class: center, middle  <!-- Adjust the room number and name --> Topic: to be chosen <br> Room: HT - 01.70 Ferdinand Peeters <br> Date: **24/02/2025** (Monday!), from **10:00** to **12:30** <br> **Help** needed with technical setup? You are welcome from **9:45am**