class: center, top  <!-- Do not forget to adapt the presentation title in the header! --> <!-- Adjust the presentation to the session. Focus on the challenges, this is not a coding tutorial. Note, to include figures, store the image in the `/docs/assets/images` folder and use the jekyll base.url reference as done in this template or see https://jekyllrb.com/docs/liquid/tags/#links. using the scale attribute , you can adjust the image size. --> <!-- Adjust the day, month --> # 16 DECEMBER 2025 ## INBO coding club <!-- Adjust the room number and name --> Herman Teirlinck<br> 01.71 - Frans Breziers<br> Christmas edition 🎅 --- class: left, top # Reminders 1. Did we confirm the room reservation on the _roomie_? 2. Did we start the recording? Today we stop at __12pm__! It's Christmas lunchbox with the "FAIR fair", organised by the INBO data stewards. --- class: center, middle <!-- Create a new badge using Inkscape based on the assets/images/coding_club_badges.svg file -->  Long title: __"from file to frames: mastering data import in R"__ --- class: center, top # How to get started? Check the [Each session setup](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup) to get started. # First time coding club? Check the [First time setup](https://inbo.github.io/coding-club/gettingstarted.html#first-time-setup) section to setup. --- class: left, top # Packages used today - [readr](https://readr.tidyverse.org/): R package for reading rectnagular data from delimited files, e.g. csv, tsv and much more! Use in challenge 1. - [jsonlite](https://github.com/jeroen/jsonlite): R package for reading and writing JSON data. Used in Challenge 1. - [arrow](https://arrow.apache.org/docs/r/): R package for reading and writing Apache Arrow files, including Parquet files. Based on the [Apache Arrow C++ library](https://arrow.apache.org/docs/cpp/index.html). Used in challenge 2. - [dplyr](https://dplyr.tidyverse.org/): R package for data manipulation. It works smoothly also with Parquet files via arrow. Used in challenge 2 and 3. - [readxl](https://readxl.tidyverse.org/): R package for reading Excel files (.xls and .xlsx). Used in challenge 3. - [googlesheets4](https://googlesheets4.tidyverse.org/): R package for reading and writing Google Sheets. Used in challenge 3. - [tidyr](https://tidyr.tidyverse.org/): R package for data tidying. Used in challenge 3. - [googledrive](https://googledrive.tidyverse.org/): R package to interact with Google Drive. Used in Bonus Challenge. --- class: left, top ## Install and load packages ```r # Load the packages and install if needed required_packages <- c( "readr", "dplyr", "tidyr", "jsonlite", "readxl", "googlesheets4", "arrow", "googledrive" ) # Install packages not yet installed installed_packages <- required_packages %in% rownames(installed.packages()) if (any(installed_packages == FALSE)) { # Install packages not yet installed install.packages(required_packages[!installed_packages]) } # Load packages invisible(lapply(required_packages, library, character.only = TRUE)) ``` --- class: left, top ## Cheat sheets or getting started resources - The "data import cheatsheet" (see image below) is a cheatsheet for three tidyverse packages: [readr](https://readr.tidyverse.org/), [readxl](https://readxl.tidyverse.org/) and [googlesheets4](https://googlesheets4.tidyverse.org/). Available as [pdf](https://github.com/inbo/coding-club/blob/master/cheat_sheets/20250130_cheat_sheet_data_import.pdf) or [html](https://rstudio.github.io/cheatsheets/html/data-import.html). - The arrow cheatsheet ([pdf](https://github.com/inbo/coding-club/blob/main/cheat_sheets/20251216_cheat_sheet_arrow)) is less fancy than the tidyverse one, but contains exactly what you need to work with the [arrow](https://arrow.apache.org/docs/r/) R package. - The [Getting Started with JSON and jsonlite](https://jeroen.r-universe.dev/articles/jsonlite/json-aaquickstart.html) page is not a cheat sheet, but you don't need more to get started with JSON files in R.  --- class: left, top 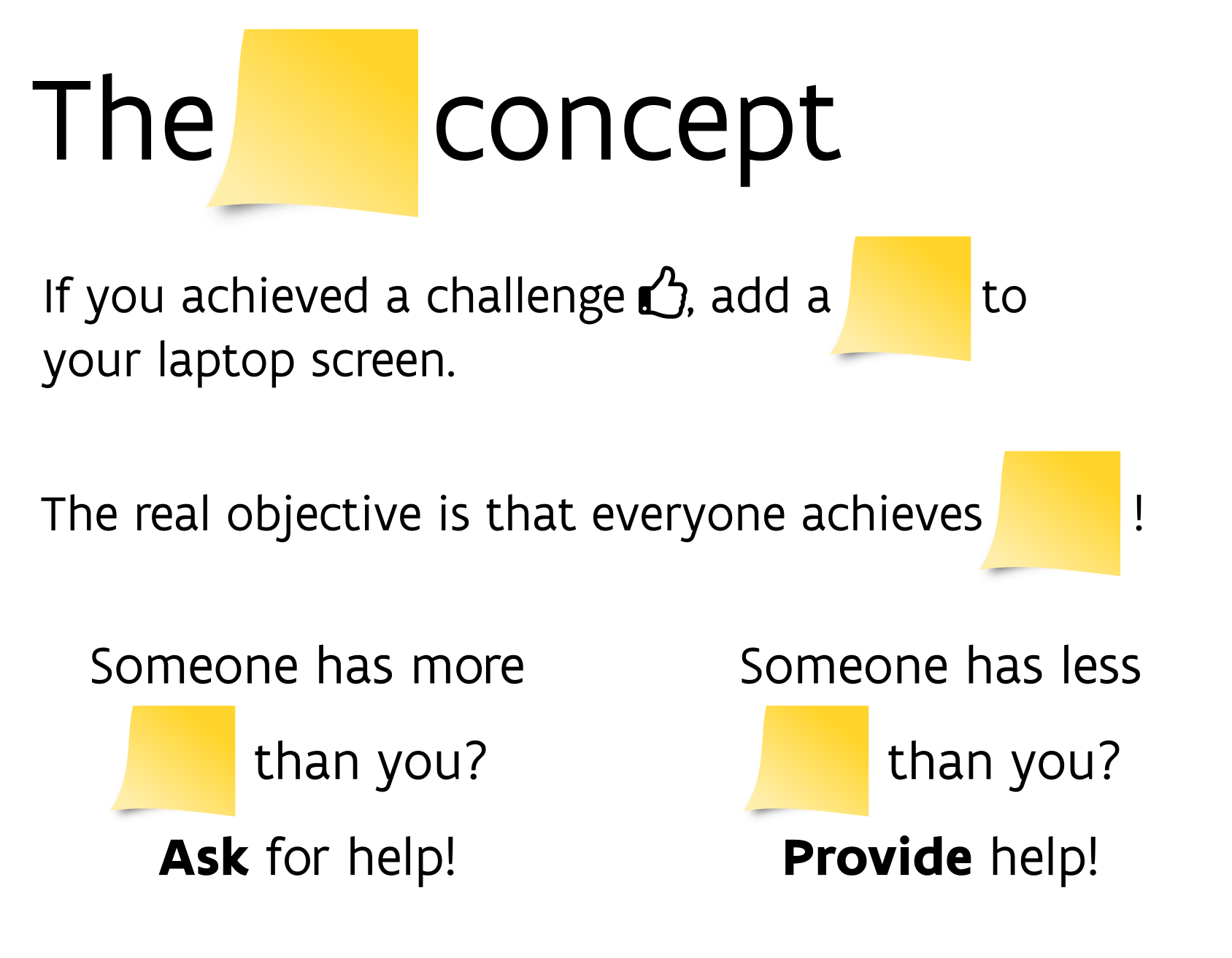 <br> No yellow sticky notes online. We use hackmd (see next slide) but basic principle doesn't change. --- class: center, top ### Share your code during the coding session! <!-- Create a new hackmd file and replace this link (twice!) --> Go to https://hackmd.io/bH5VSSwAQ46FXetH_NKn1Q?edit <iframe src="https://hackmd.io/bH5VSSwAQ46FXetH_NKn1Q?edit" height="450px" width="800px"></iframe> --- class: left, top # JSON What's [JSON](https://en.wikipedia.org/wiki/JSON)? JSON the acronym for JavaScript Object Notation. It is a lightweight data-interchange format that is easy for humans to read and write, and easy for machines to parse and generate. It is often used for transmitting data in web applications (e.g., sending some data from the server to the client, so it can be displayed on a web page, or vice versa). One example: GBIF API responses! See below the info you get about the occurrence with `occurrenceID` [5908536615](https://api.gbif.org/v1/occurrence/5908536615). Corresponding web page: https://www.gbif.org/occurrence/5908536615. 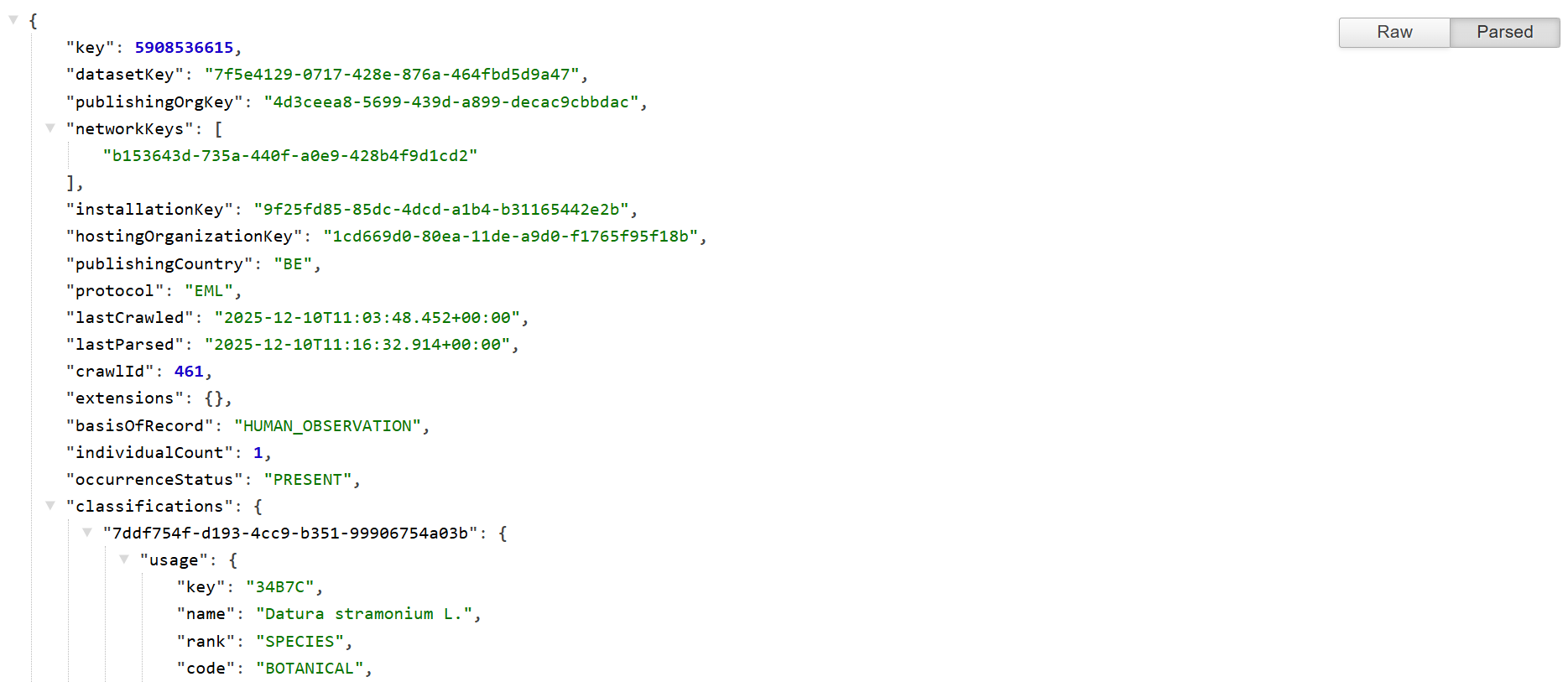 --- class: left, top # Parquet What are Parquet files? From official [Parquet](https://parquet.apache.org/docs/overview/) documentation: > "Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides high performance compression and encoding schemes to handle complex data in bulk and is supported in many programming languages and analytics tools." But why the R package is called Arrow? What's Arrow actually? From official [Arrow](https://arrow.apache.org/) documentation: > "Apache Arrow defines a language-independent columnar memory format for flat and nested data, organized for efficient analytic operations on modern hardware like CPUs and GPUs." Parquet is optimized for "data at rest" while Arrow is optimized for "data in motion" - and they're designed to work together as part of a unified data pipeline: many modern data tools use this combination - storing data in Parquet format on disk for efficient storage and querying, while using Arrow format in memory for fast processing. --- class: left, top # Download data and code - Download everything automatically via `inborutils::setup_codingclub_session()` - manually*, from [data/20251216](https://github.com/inbo/coding-club/blob/master/data/20251216/) and [src/20251216](https://github.com/inbo/coding-club/blob/master/src/20251216). Place the R script in your folder `src/20251216/` and data in `data/20251216/`. There is still a directory from Google Drive you have to download manually: [20251216_gbif_parquet_be_2022](https://drive.google.com/drive/folders/19-wOEEu24zwXqbPxIU1bg_ChG-PFu_KF). Place it in your folder `data/20251216/20251216_gbif_parquet_be_2022`. <small>* __Note__: check the getting started instructions on [how to download a single file](https://inbo.github.io/coding-club/gettingstarted.html#each-session-setup)</small> --- class: left, top # Data and code files description 1. Zenodo deposit [MH_ANTWERPEN - Western marsh harriers (Circus aeruginosus, Accipitridae) breeding near Antwerp (Belgium)](https://zenodo.org/records/10054153)*: an INBO bird tracking dataset. It contains animal tracking data collected by the LifeWatch GPS tracking network for [large birds](http://lifewatch.be/en/gps-tracking-network-large-birds). 2. [20251216_MH_ANTWERPEN-gps-2018.csv.gz](https://github.com/inbo/coding-club/blob/master/data/20251226/20251216_MH_ANTWERPEN-gps-2018.csv.gz): compressed CSV file with GPS tracking data. Same as `MH_ANTWERPEN-gps-2018.csv.gz` in the Zenodo deposit. 3. [20251216_gbif_parquet_be_2022](https://drive.google.com/drive/folders/19-wOEEu24zwXqbPxIU1bg_ChG-PFu_KF?usp=drive_link): Google folder with a Parquet file containing all occurrences with spatial coordinates and no geospatial issues taken in Belgium from 2023**. 4. [20251216_list_butterflies](https://docs.google.com/spreadsheets/d/1hUd_qWIQ5Lg1g1cfxKyBkD56iUU9lcVeKV6bkN02Ing/edit?usp=sharing): Google Sheet with butterfly species observed during transect counts in 2024 and 2025. Totally made up data! 5. [20251226_butterfly_transect_counts_raw.xls](https://github.com/inbo/coding-club/blob/master/data/20251226/20251226_butterfly_transect_counts_raw.xls): Excel file with butterfly transect counts. 6. [20251216_challenges.R](https://github.com/inbo/coding-club/blob/master/src/20251216/20251216_challenges.R): R script to start from. <small>\* Spanoghe, G., Desmet, P., Milotic, T., Janssens, K., De Regge, N., Vanoverbeke, J., & Bouten, W. (2023). MH_ANTWERPEN - Western marsh harriers (Circus aeruginosus, Accipitridae) breeding near Antwerp (Belgium) [Data set]. Research Institute for Nature and Forest (INBO). https://doi.org/10.5281/zenodo.10054153 </small> <small>\*\* Derived from "GBIF.org (15 December 2025) GBIF Occurrence Download https://doi.org/10.15468/dl.kcdrmt</small> --- background-image: url(/assets/images/background_challenge_1.png) class: left, top # Challenge 1A - zenodo and readr We know to read tabular data locally saved on our machine using readr. But readr can do more! And that's what we will explore now. Go to the Zenodo deposit [MH_ANTWERPEN - Western marsh harriers (Circus aeruginosus, Accipitridae) breeding near Antwerp (Belgium)](https://zenodo.org/records/10054153) (zenodo DOI: https://doi.org/10.5281/zenodo.3550093) 1. Use readr package to read the file `MH_ANTWERPEN-reference-data.csv` into R as a data frame called `ref_data`. Pay attention to the column specifications. They must be the same as described in the zenodo `datapackage.json `. Hint: see the section "Column specification with readr" in the data import cheatsheet. Notice also that the datetime format as specified in the zenodo metadata, `"%Y-%m-%d %H:%M:%S.%f"`, is not supported by readr. Check lubridate [documentation](https://lubridate.tidyverse.org/reference/parse_date_time.html#details) to see how to handle __fractional seconds__ in R. lubridate is not needed though. 2. Use readr package to read the GPS zipped file `20251216_MH_ANTWERPEN-gps-2018.csv.gz` into R as a data frame called `gps_data`. 3. Use readr package to read the same file (without prefix `20251216_`) from zenodo into R as a data frame called `gps_data_url`. --- background-image: url(/assets/images/background_challenge_1.png) class: left, top # Challenge 1B - zenodo, jsonlite and inborutils 1. Use jsonlite to read the `datapackage.json` file from the zenodo into R as a list called `metadata`. If you did everything correct, you should get a list of 3 elements: `id`, `profile` and `resources`. Explore it and compare it with the `datapackage.json` file on zenodo. 2. Sometimes you need to download a zenodo deposit programmatically: there is a function in our loved [inborutils](https://inbo.github.io/inborutils/reference/index.html) R package, didnt' you know? Find it and use it to download the entire zenodo deposit into the folder `data/20251216/mh_antwerpen_data`.* <small>* Thanks Hans and Floris to write this very useful function!</small> --- class: left, top # Intermezzo - Frictionless Data Packages The zenodo deposit you work with in challenge 1 is an example of a [Frictionless Data Package](https://datapackage.org/), one of the standards within [Frictionless](https://frictionlessdata.io/): *an open-source toolkit that brings simplicity to the data experience - whether you're wrangling a CSV or engineering complex pipelines.* __Frictionless Data Package__ is the fundamental building block of Frictionless. A Data Package is a simple container format and standard to describe and package a collection of (tabular) data. It is typically used to publish FAIR and open datasets. Standards based on Frictionless Data Package exist for specific domains: - [Camera Trap Data Package](https://camtrap-dp.tdwg.org/): a community-developed data exchange format for camera trap data. A Camtrap DP is a Frictionless Data Package. a specific type of Frictionless Data Package. - [Darwin Core Data Package](https://gbif.github.io/dwc-dp/#dp) (DwC-DP): an exchange format for biodiversity data. It extends the Frictionless Data Package specification as an implementation for the Darwin Core Conceptual Model. In Public Review phase: it will be the future of GBIF data downloads! --- class: left, top # Intermezzo - Frictionless Data Packages And do you know that there is an R package to read and write Frictionless Data Packages? The [__frictionless__](https://docs.ropensci.org/frictionless/) R package! Its maintainer is our INBO colleague Peter Desmet! Move to Bonus challenge 1 if you cannot wait using it to import the zenodo package used in challenge 1! --- background-image: url(/assets/images/background_challenge_2.png) class: left, top # Challenge 2 - Parquet, arrow and dplyr Use the [arrow](https://arrow.apache.org/docs/r/) R package and dplyr to open and explore the Parquet file `20251216_gbif_parquet_be_2022`. It contains all occurrences with spatial coordinates and no geospatial issues taken in Belgium from 2023 and it's 201MB. Be sure to have enough disk space. Derived from GBIF download with `downloadKey` [0054090-251120083545085](https://www.gbif.org/occurrence/download/0054090-251120083545085)) using [rgbif](https://docs.ropensci.org/rgbif/). 1. What are the columns in the GBIF dataset? Hint: same as you do with a standard data frame in R. 2. How many occurrences are in the GBIF dataset? 3. How many unique species are in the GBIF dataset? 4. What are the top 10 most observed species in terms of number of occurrences? Do not take into account observations at higher rank: species must be not NA. 5. What is the temporal coverage of the GBIF dataset (min and max datetime of observation)? 6. Repeat 5 but take into account only occurrences with datetime specified up to the day (i.e. ignore occurrences with only year or year and month specified). 7. How many occrrences are per occurrence status? Hint: check the section "Downloading a simple parquet from GBIF" from the blog post [Using Apache Arrow and Parquet with GBIF-mediated occurrences](https://data-blog.gbif.org/post/apache-arrow-and-parquet/). --- background-image: url(/assets/images/background_challenge_3.png) class: left, top # Challenge 3A - Google Spreadsheets INBO uses Google Workspace as collaborative work environment and data storage. So, it's good to know how to read data from Google Sheets into R. 1. Use the googlesheets4 R package to read the Google Sheet [20251216_list_butterflies](https://docs.google.com/spreadsheets/d/1hUd_qWIQ5Lg1g1cfxKyBkD56iUU9lcVeKV6bkN02Ing/edit?usp=sharing) into R as two data frames, called `butterflies_2025` and `butterflies_2024`. Tip: you don't need authentication to read public Google Sheets. Check how to disable authentication in the [googlesheets4 auth](https://googlesheets4.tidyverse.org/articles/auth.html) vignette. 2. Are these two data frames tidy? If not, can you tidy them up? Apply the tidy data principles*: - A __dataset__ is a collection of __values__ (numbers, strings, ...). - Every value belongs to a __variable__ and an __observation__ - A variable contains all values that measure the same underlying attribute (e.g. measurement datetime, scientific name, transect identifier) across units. - An observation contains all values measured on the same unit (e.g. an observation of species A at day 1 in transect a1) across attributes. Variable = column; Observation = row; Observational unit = table (data frame). <small> \* More info about tidy data in ["Tidy Data"](https://vita.had.co.nz/papers/tidy-data.pdf). Wickham, H. (2014). Tidy Data. Journal of Statistical Software, 59(10), 1-23. </small> --- background-image: url(/assets/images/background_challenge_3.png) class: left, top # Challenge 3B - readxl and tidy data Use [readxl](https://readxl.tidyverse.org/) R package to load the data from the Excel file `20251216_butterfly_transect_count_raw.xlsx` and save at least a data frame called `transect_counts` with three columns: - species: species name - section: transect section identifier - n: number of individuals observed The Excel file is a great example of dataset which is very readable by humans, but in a "messy format" for computers. Can you tidy it up? Apply the tidy data principles mentioned in challenge 3A. Aside the transect counts, Which are the other observational units contained in the file? How to link all tables? You will need to create unique identifiers. Which columns can be used for this? This exercise can take a while and can require some other tidyverse packages e.g. tidyr, dplyr, stringr, purrr. --- class: left, top # Bonus challenges 1. Load the zenodo deposit used in challenge 1 in R using the frictionless R package. It should be very easy to read the "gps" and the "reference-data" resources! 2. We downloaded the Parquet file for challenge 2 from Google Drive manually. How to do it programmatically in R? Use the [googledrive](https://googledrive.tidyverse.org/) R package to download the file from Google Drive. It can take a while. 3. Try to access the [latest gbif snapshot]("s3://gbif-open-data-eu-central-1/occurrence/2021-11-01/occurrence.parquet") using the [arrow](https://arrow.apache.org/docs/r/) R package. Use some dplyr functions to see how fast you can get the answer. Try e.g. the code in the [GBIF blogpost](https://data-blog.gbif.org/post/apache-arrow-and-parquet/) or try to get the same results as in challenge 2. 4. Download first the Parquet file related to challenge 2 from GBIF directly: https://doi.org/10.15468/dl.kcdrmt. Try to open it with arrow. --- class: left, top # The package of the month. Oberon's choice [Officer](https://davidgohel.github.io/officer/) is a R package to manipulate and format Word documents. It is a great tool to create reports, certificates, or any other document you need to write in Word format. It is a very powerful package, but it is also very easy to use. Check the related [officeverse]((https://ardata-fr.github.io/officeverse/)) (it's a bookdown!) (officer + extensions) and the [package documentation](https://davidgohel.github.io/officer/).  --- class: left, top # Resources - Comprehensive [solutions](https://github.com/inbo/coding-club/blob/main/src/20251216/20251216_challenges_solutions.R) are available on GitHub. You can opt to download the solutions automatically by using `inborutils::setup_codingclub_session("20251216")`. - The edited [video recording](https://vimeo.com/1154956476) is available on our [vimeo channel](https://vimeo.com/user/8605285/folder/1978815). - [readr](https://readr.tidyverse.org/): R package for reading rectnagular data from delimited files, e.g. csv, tsv. - [arrow](https://arrow.apache.org/docs/r/): R package for reading and writing Apache Arrow files, including Parquet files. Based on the [Apache Arrow C++ library](https://arrow.apache.org/docs/cpp/index.html). - [jsonlite](https://github.com/jeroen/jsonlite): R package for reading and writing JSON data. - [quickstart vignette](https://jeroen.r-universe.dev/articles/jsonlite/json-aaquickstart.html) for getting started with JSON and jsonlite. - [readxl](https://readxl.tidyverse.org/): a tidyverse R package for reading Excel files (.xls and .xlsx). - [googlesheets4](https://googlesheets4.tidyverse.org/): a tidyverse R package for reading and writing Google Sheets. - [inborutils](https://inbo.github.io/inborutils/): INBO made R package with utility functions, among others downloading zenodo files. - [frictionless](https://docs.ropensci.org/frictionless/): R package to work with Frictionless Data Packages. - [Camtrap DP](https://camtrap-dp.tdwg.org/): Data exchange format for camera trap data, a specific type of Frictionless Data Package. - [googledrive](https://googledrive.tidyverse.org/): a tidyverse R package to interact with Google Drive. - [Officer](https://davidgohel.github.io/officer/): R package to manipulate and format Word documents. --- class: center, middle  <!-- Adjust the room number and name --> Room: HT - 01.55 - Hilda Ram <br> Date: __26/01/2026 Monday(!)__, van __10:00__ tot __12:30__ <br> Subject: not yet decided <br> (registration announced via DG_useR@inbo.be)